一个真实的场景:
某汽车零部件企业的CIO最近很焦虑。产线上有500多个传感器,ERP、MES、SCADA系统齐全,每天产生的数据量以TB计。
当管理层提出“上AI质检”时,技术团队才发现——传感器数据的时间戳对不上,工艺参数散落在不同系统里,ERP里的“订单”和MES里的“工单”根本没法关联。数据很多,但AI读不懂。
2026年政府工作报告首次提出“打造智能经济新形态”之后,很多企业开始追问:《光明日报》4月初的一篇报道给出了一个清晰的定义:智能经济是以人工智能为核心,通过数据、算力、算法的集群式突破,重构传统生产要素配置的新型经济形态。同时,据该报道,到今年3月,我国日均token调用量已超过140万亿,相比2024年初的1000亿增长了1000多倍。政策层面的“智能经济”和企业车间的“智能经济”,中间隔着一条很深的沟。
中国工业互联网研究院院长鲁春丛在一次专访中打了个比方:
很多制造业企业不缺数据,缺的是能被AI理解的数据。1.多元异构:传感器的时间序列数据、质检摄像头拍下的视频、工艺文件里的文本、设计部门的图纸——格式各异,标准不一。AI不是人,它没法像工程师那样“看一眼就懂”。2.多级分布:数据分散在设备、产线、车间,以及ERP、MES、SCADA这些不同的系统里。每个系统有自己的“语言”:ERP里叫“订单”,MES里叫“工单”,SCADA里叫“批次号”。如果没人告诉AI这三个词指的是同一件事,数据孤岛就依然存在。3.深度耦合:工业数据背后藏着复杂的物理机理、工艺知识,还有老师傅多年积累的“隐性经验”。数据之间的关系不是简单的“A导致B”,而是“A在某种工况下,通过C的中介,影响D”。这种复杂度,让很多现成的AI模型直接“水土不服”。结果是:企业花了钱建系统、采数据,最后发现AI用不上——因为数据“沉睡”了。
面对这个困境,鲁春丛提出了一个系统性的解决思路,可以概括为“1套智能基础设施+3类高质量数据集”。
“1套智能基础设施”的核心,不是再建一个数据中台,而是打破“数据孤岛”的底层逻辑。过去企业做信息化,思路是“把数据集成到一个平台上”。但在AI时代,数据汇聚不等于数据连通。鲁春丛强调,需要推进IT(信息技术)、CT(通信技术)、OT(运营技术)和DT(数据技术)的“4T融合”——建立统一的语义模型,让AI真正理解数据之间的实体关系和因果链条。“3类高质量数据集”则是在这个基座上,分类建设AI的“燃料库”:
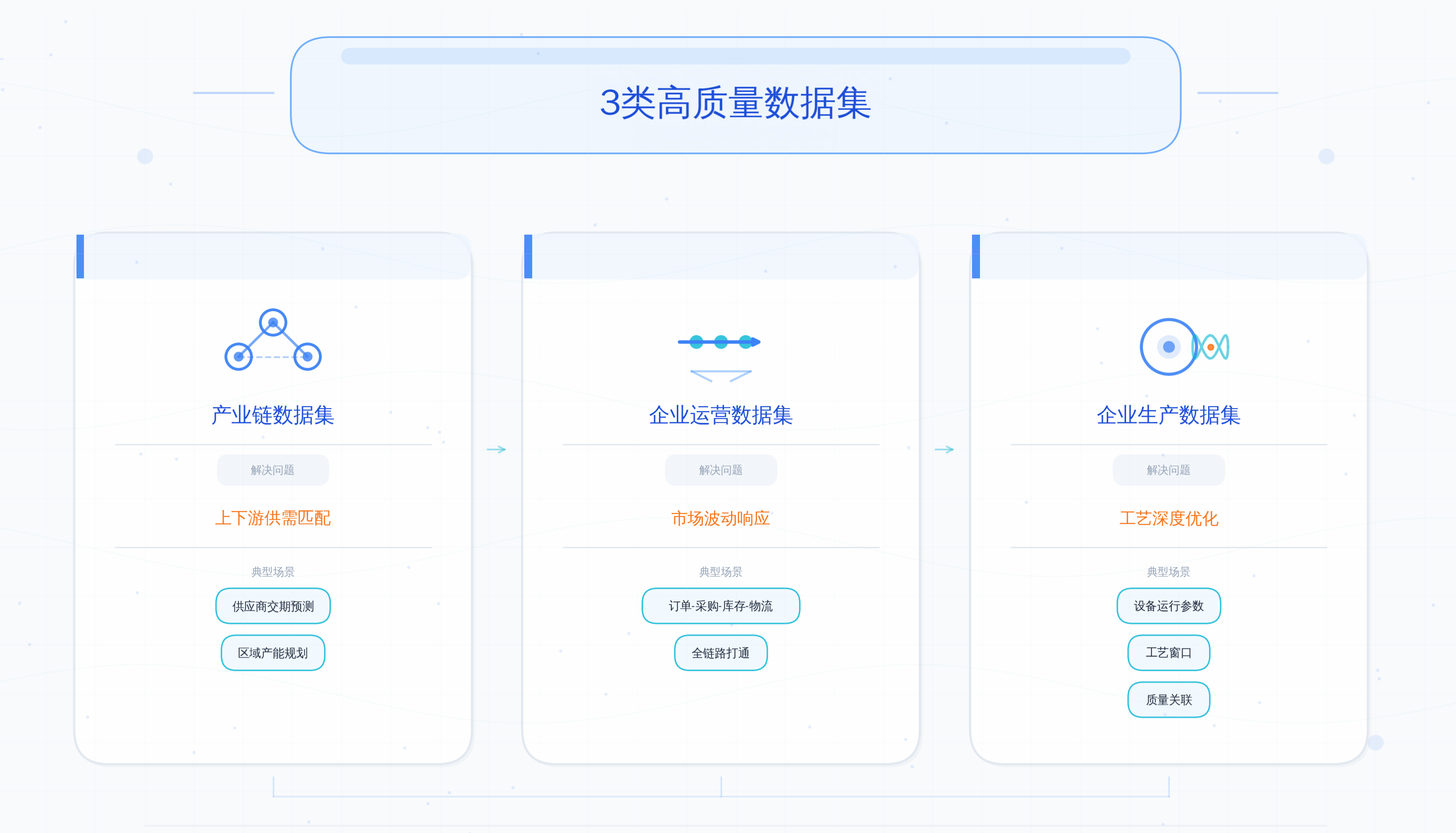
鲁春丛特别提到,企业生产数据集是“最宝贵的语料”——它深入设备运行、工艺参数这些“深水区”,是训练工业大模型最核心的“燃料”。但这也是最难建设的部分,因为它需要把老师傅的经验“翻译”成AI能理解的规则。
数据觉醒之后,怎么产生价值?
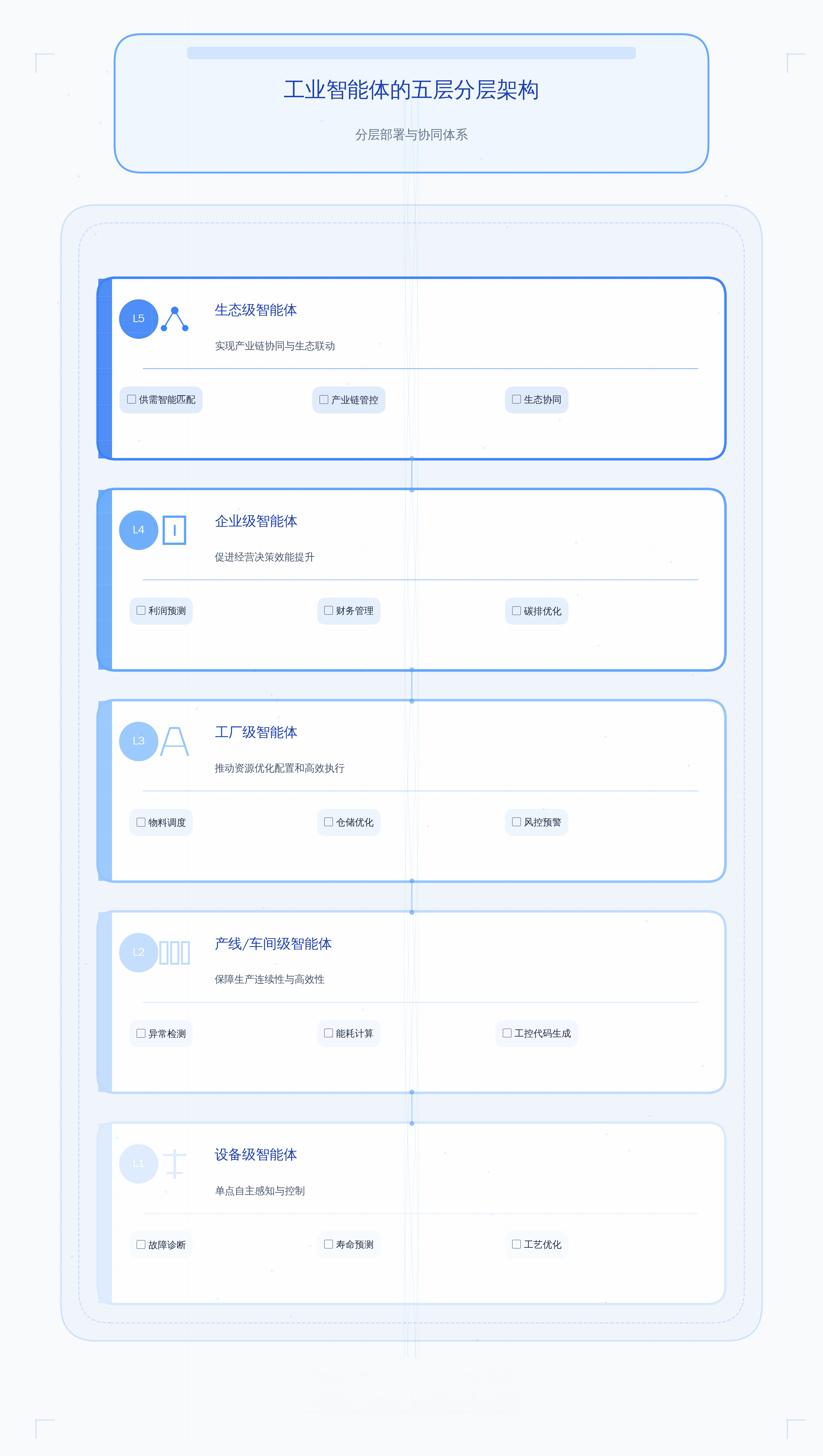
2026年初,工信部等八部门印发的《“人工智能+制造”专项行动实施意见》给出了一个方向:到2027年,推出1000个高水平工业智能体。IDC的研究经理杜雁泽有一个观察:工业智能体正在从“被动工具”转变为“可自主执行的数字员工”。这个转变的微妙之处在于——不是功能变多了,而是角色变了。鲁春丛在多个场合提出了一个五级分层架构:
这个架构的核心逻辑是“大模型指挥、小模型执行”——
云侧的大模型负责复杂决策,边缘侧的小模型负责实时执行,形成“感知—决策—执行”的闭环。据《经济参考报》报道,美的在设备维护、模具管理等智能体应用方面取得显著成效;海尔方面也称智能体应用带来研发效率的大幅提升。但需要提醒的是:这些是头部企业的实践,不代表所有企业都能复制。同时,IDC预测中国工业企业AI支出正从“概念投入期”进入“可规模化扩展期”,未来几年有望保持较高增速——但具体增速和规模,不同机构的判断存在差异。
鲁春丛反复强调一句话:推进“AI+制造”绝不能搞“一刀切”,必须坚持“分业推进、分级推进”。
这个判断很务实。不同规模、不同阶段的企业,面临的痛点完全不同:行业龙头和链主企业:策略应该是“顶格推进”——开放自己的应用场景,牵头建设产业链协同的高质量数据集,带动上下游一起打通数据。这既是能力,也是责任。专精特新企业:更适合“单点突破”——选一个高价值场景(比如质检、排产),快速验证ROI,不要一上来就做全厂智能化。广大中小微企业:现实的选择是“小快轻准”——依托国家工业互联网大数据中心或公共云平台,用订阅制的方式部署轻量化的边缘智能体,解决最迫切的单点痛点。在评估投入产出时,鲁春丛建议关注三个因素,值得参考:1.防脱节:以解决实际业务痛点为导向,不要为了上AI而上AI。2.重安全:严守“数据物理不出域”,采用联邦学习(一种数据不出域的联合建模技术)、边缘计算等技术保护商业秘密。3.算长远:评估ROI不能只看软硬件采购成本,更要看良率提升、能耗下降、研发周期缩短,以及供应链的“韧性”和“响应速度”。
《光明日报》的报道中,西南财经大学大数据研究院院长寇纲提了一个值得警惕的判断:“规模优势不等于竞争优势,科技实力还未完全转化为产业竞争力。”
这句话的意思是:中国有全球最完备的工业体系、海量的数据资源、超大规模的市场——这些是优势,但优势不会自动变成竞争力。如果数据沉睡、模型泛化、智能体碎片化,再大的规模也只是“虚胖”。国务院2025年发布的《关于深入实施“人工智能+”行动的意见》设定了三阶段目标:2027年智能经济核心产业规模快速增长,2030年成为经济发展的重要增长极,2035年全面步入智能经济和智能社会新阶段。这些时间节点传递了一个信号:2026到2030年是政策推进的关键期。企业的智能化改造,需要从“数据觉醒”开始,量力而行,循序渐进。当然,这并非没有风险——对于数据基础薄弱、人才储备不足的中小企业而言,盲目跟风可能比观望更危险。
回到开头那个焦虑的CIO。
很多企业把“上AI”当作第一步,但实际上,“理数据”才是第一步。没有高质量的数据集,再先进的模型也是无米之炊;没有统一的数据语义,再多的智能体也是各自为战。智能经济不是遥远的概念。当机器人开始协同“上班”,当机械手能够穿针引线,当人工智能从“能聊天”变成“能办事”——制造业的竞争规则已经在改变。但改变的方向,不是谁先用上AI,而是谁先让AI读懂自己的数据。若您正在规划相关方向,欢迎私信交流具体情境,我们愿意分享更多一线观察。
本文核心资料来源:《智能经济形态日益焕新》,《光明日报》2026年4月2日;《智能体成拉动制造业转型新引擎》,《经济参考报》2026年3月9日;鲁春丛院长专访,《21世纪经济报道》2026年3月;《国务院关于深入实施「人工智能+」行动的意见》,2025年8月;

关注【科瑞斯达】官方公众号,了解更多前沿资讯及落地经验